
游戏笔记本的“风扇噪声”和侧面出风口的“热浪烤手”是困扰游戏玩家的两大难解之题。而近年来,越来越多的笔记本已经悄悄取消了侧面出风口,风扇噪声也日渐友好。这不仅归功于处理器高能低耗的代际提升,还得益于英特尔于2022年10月公布的风扇内吹黑科技,专利“Methodsand Apparatus to Cool Electronic Devices”(内部代号:Esther Island),此项黑科技通过风道设计的整体改变,由向外“吹热风”,变成向内“灌凉风”,从而为全球的游戏本、轻薄本、甚至掌机等英特尔赋能的产品带来高能、低温、低噪、低成本的散热解决方案,为游戏玩家提供了更友好的I/O接口,造福游戏玩家,并实现出色的畅玩体验。
向外“吹热风”变成向内“灌凉风”
英特尔的Esther Island黑科技,是将风扇的“散热风向”由向外“吹热风”调整为向内“灌凉风”。风向的改变,让机身内部从“负压”变成“正压”,并通过良好的内部密封,直接让机身内的温度下降,使散热更高效,并释放更高性能,提高了系统的功耗天花板。
在黑科技加持下,机身的散热点也得到了优化。热量集聚的点位从键盘和触摸板附近,向机身后部转移,相对于直接减少热量集聚区域的温度,这样的转移方式能够让用户更直观地感受到温度的降低,让笔记本C面不再成“烫手山芋”,解决烫手问题。
优化系统架构,完善接口排布
除了散热降温,这项黑科技还能够优化系统架构,平衡系统设计,改善主板布局,完善接口排布,节省散热材料,降低整机成本和重量。由于风向向内,因此,既不需要侧面散热鳍片,也不需要在侧面布置出风口,这就为在机身侧面布置HDMI、USB等I/O扩展接口提供了便利,更便于用户使用和扩展,丰富和完善了用户体验。
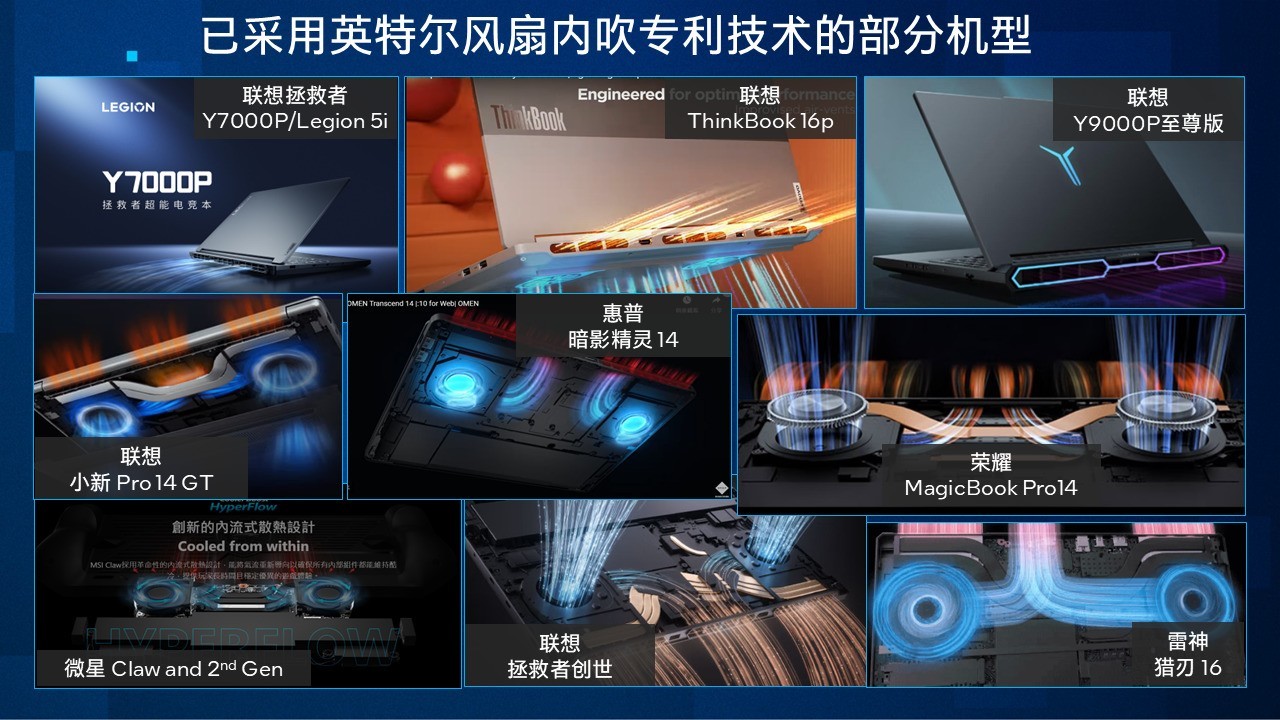
效果显著市场认可,客户积极跟进
目前,市面上已经有越来越多的机型采用了英特尔的此项散热黑科技,联想、惠普、微星、荣耀等厂商迅速跟进,这项黑科技被市场和产业链逐渐认可。近期上市并采用该技术的主流机型包括联想拯救者Y9000P至尊版游戏本,联想小新Pro14/16 GT、荣耀MagicBook Pro 14等轻薄本,还有MSI Claw 8 AI 掌机等,涵盖了游戏,轻薄,商务以及掌机新形态,完美诠释了这项技术的普适性。
在采用了此项散热黑科技的某款笔记本产品上,实现了“一升四降”的效果。使用Prime95+Furmark测试,对比常规散热方案,在性能上,能够把CPU的稳定功耗从74W提高到90W;在表面温度上,把D面最热点温度从59.8摄氏度降低到49.6摄氏度;在成本方面可以减少大约5美金的成本支出;在重量上,散热模块可减少大约15%的重量;另外,在噪音上也得到显著下降。
默默耕耘,只为超群体验
无论是能效比大幅提升的酷睿Ultra处理器,还是与产业深度合作的游戏优化,以及Thunderbolt 5、Wi-Fi 7等连接技术,在加上英特尔这项内吹黑科技的赋能,都是英特尔以用户中心,倾力打磨产品,释放性能潜力。未来,英特尔将继续与产业共同携手,为提升每一分性能、提供出色用户体验而全力以赴,造福每一位用户。
随着酷睿Ultra 200HX处理器的新品发布,越来越多OEM厂商的英特尔平台机型新模具使用了这项技术,欢迎各位玩家多多关注,抢先感受酷冷高能的游戏体验!
本文属于原创文章,如若转载,请注明来源:局域过热到全域恒温,英特尔内吹专利解析https://nb.zol.com.cn/981/9812742.html